多核机器上的 Node.js
Node.js 看起来很有趣,但是我必须错过一些东西 - Node.js 不是调整为仅在单个进程和线程上运行吗?
那么它如何针对多核 CPU 和多 CPU 服务器进行扩展呢?毕竟,尽可能快的单线程服务器是很棒的,但是对于高负载,我想使用几个 CPU。使应用程序更快也是如此 - 今天的方式似乎是使用多个 CPU 并并行化任务。
Node.js 是如何融入这张图片的?它的想法是以某种方式分发多个实例还是什么?
[这篇文章是 2012-09-02 最新的(比上面更新)。]
Node.js 绝对可以在多核机器上扩展。
是的,Node.js 是每个进程一个线程。这是一个非常深思熟虑的设计决策,并且消除了处理锁定语义的需要。如果您不同意这一点,您可能还没有意识到调试多线程代码是多么困难。要更深入地解释 Node.js 进程模型及其以这种方式工作的原因(以及它永远不支持多线程的原因),请阅读 my other post。
那么如何利用我的 16 芯盒子呢?
两种方式:
对于像图像编码这样的大型计算任务,Node.js 可以启动子进程或向其他工作进程发送消息。在此设计中,您将有一个线程管理事件流,而 N 个进程执行繁重的计算任务并占用其他 15 个 CPU。
为了扩展 Web 服务的吞吐量,您应该在一个机器上运行多个 Node.js 服务器,每个核心一个,并在它们之间拆分请求流量。这提供了出色的 CPU 关联性,并且将随核心数几乎线性地扩展吞吐量。
扩展 Web 服务的吞吐量
从 v6.0.X 开始,Node.js 直接包含了 the cluster module,这使得设置可以在单个端口上侦听的多个节点工作程序变得容易。请注意,这与通过 npm 提供的较旧的 learnboost“集群”模块不同。
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
http.Server(function(req, res) { ... }).listen(8000);
}
工作人员将竞争接受新的连接,负载最少的进程最有可能获胜。它工作得很好,并且可以在多核机器上很好地扩展吞吐量。
如果您有足够的负载来处理多个内核,那么您还需要做更多的事情:
在 Nginx 或 Apache 之类的 Web 代理后面运行您的 Node.js 服务 - 可以进行连接限制(除非您希望过载条件完全关闭盒子)、重写 URL、提供静态内容和代理其他子服务。定期回收您的工作进程。对于长时间运行的进程,即使是很小的内存泄漏最终也会累加。设置日志收集/监控
PS:Aaron 和 Christopher 在另一篇文章的评论中进行了讨论(在撰写本文时,它是最重要的帖子)。对此有几点评论:
共享套接字模型非常方便允许多个进程侦听单个端口并竞争接受新连接。从概念上讲,您可以考虑预先分叉的 Apache 这样做,但需要注意的是每个进程将只接受一个连接然后死掉。 Apache 的效率损失在于分叉新进程的开销,与套接字操作无关。
对于 Node.js,让 N 个 worker 在一个 socket 上竞争是一个非常合理的解决方案。另一种方法是设置一个像 Nginx 这样的机上前端,并将代理流量分配给各个工作人员,在工作人员之间交替分配新的连接。这两种解决方案具有非常相似的性能特征。而且,正如我上面提到的,无论如何,您可能希望 Nginx(或替代方案)在您的节点服务前面,这里的选择实际上是:
共享端口:nginx (port 80) --> Node_workers x N (sharing port 3000 w/ Cluster)
对比
个别端口:nginx (port 80) --> {Node_worker (port 3000), Node_worker (port 3001), Node_worker (port 3002), Node_worker (port 3003) ...}
可以说,单独的端口设置有一些好处(可能减少进程之间的耦合,有更复杂的负载平衡决策等),但设置起来肯定需要更多的工作,并且内置的集群模块很低-适用于大多数人的复杂性替代方案。
一种方法是在服务器上运行多个 node.js 实例,然后在它们前面放置一个负载均衡器(最好是像 nginx 这样的非阻塞式负载均衡器)。
去年夏天,Ryan Dahl 在 the tech talk he gave at Google 中回答了这个问题。套用一句话,“只需运行多个节点进程并使用合理的方式让它们进行通信。例如 sendmsg() 风格的 IPC 或传统的 RPC”。
如果您想立即动手,请查看
spark2 Forever 模块。它使生成多个节点进程变得非常容易。它处理设置端口共享,因此它们每个都可以接受到同一端口的连接,并且如果您想确保进程在死亡时重新启动,它们也会自动重生。
更新 - 2011 年 10 月 11 日:节点社区的共识似乎是 Cluster 现在是管理每台机器多个节点实例的首选模块。 Forever 也值得一看。
您可以使用 cluster 模块。检查this。
var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
// Workers can share any TCP connection
// In this case its a HTTP server
http.createServer(function(req, res) {
res.writeHead(200);
res.end("hello world\n");
}).listen(8000);
}
Node Js 支持集群以充分利用您的 CPU。如果您没有使用集群运行它,那么您可能正在浪费您的硬件功能。
Node.js 中的集群允许您创建可以共享相同服务器端口的单独进程。例如,如果我们在 3000 端口上运行一台 HTTP 服务器,它就是一台在单线程上运行在处理器单核上的服务器。
下面显示的代码允许您对应用程序进行集群。此代码为 Node.js 代表的官方代码。
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
Object.keys(cluster.workers).forEach(function(id) {
console.log("I am running with ID : " + cluster.workers[id].process.pid);
});
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
//Do further processing.
}
查看这篇文章以获得完整的tutorial
多节点利用您可能拥有的所有核心。
看看 http://github.com/kriszyp/multi-node。
对于更简单的需求,您可以在不同的端口号上启动多个节点副本,并在它们前面放置一个负载均衡器。
如上所述,Cluster 将在所有内核上扩展和负载平衡您的应用程序。
添加类似
cluster.on('exit', function () {
cluster.fork();
});
将重新启动任何失败的工人。
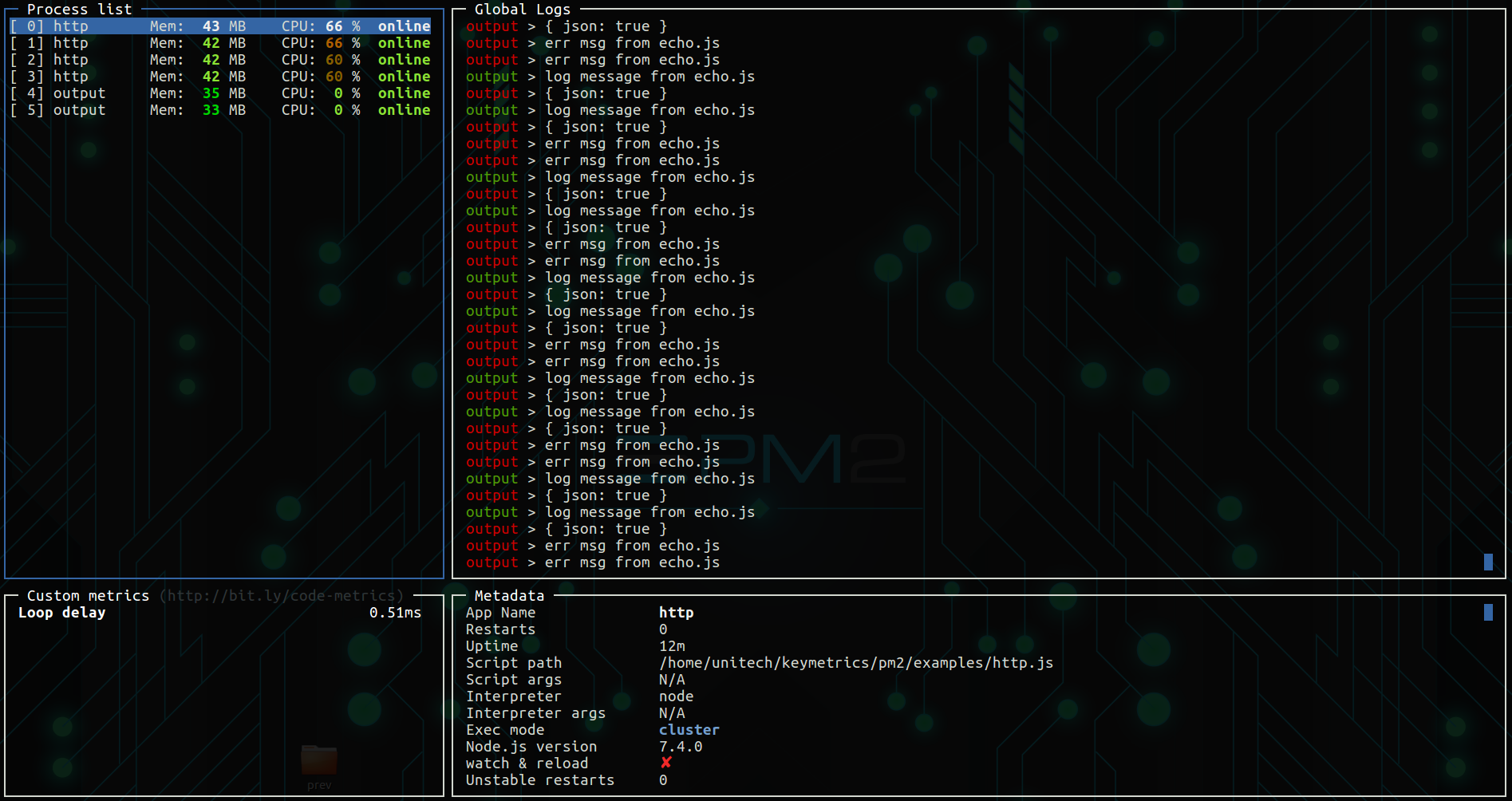
这些天来,很多人也更喜欢 PM2,它为您处理集群并提供 some cool monitoring features。
然后,在运行集群的多台机器前添加 Nginx 或 HAProxy,您将拥有多级故障转移和更高的负载能力。
未来版本的 node 将允许您分叉一个进程并将消息传递给它,Ryan 表示他希望找到一些方法来共享文件处理程序,因此它不会是一个直接的 Web Worker 实现。
目前还没有一个简单的解决方案,但它还为时过早,node 是我见过的发展最快的开源项目之一,所以期待在不久的将来会有一些很棒的东西。
Spark2 基于现在不再维护的 Spark。 Cluster 是它的继任者,它有一些很酷的特性,比如每个 CPU 核心生成一个工作进程和重生死掉的工作进程。
您可以通过将 cluster 模块与 os 模块结合使用来在多个内核上运行您的 node.js 应用程序,该模块可用于检测您拥有多少 CPU。
例如,假设您有一个在后端运行简单 http 服务器的 server 模块,并且您希望为多个 CPU 运行它:
// 依赖关系。 const server = require('./lib/server'); // 这是我们的自定义服务器模块。常量集群 = 要求(“集群”); const os = 要求('os'); // 如果我们在主线程上,则启动分叉。 if (cluster.isMaster) { // 分叉进程。 for (let i = 0; i < os.cpus().length; i++) { cluster.fork(); } } else { // 如果我们不在主线程上启动服务器。 server.init(); }
我正在使用 Node worker 从我的主进程中以一种简单的方式运行进程。在我们等待正式的方式出现时,似乎工作得很好。
这里的新手是 LearnBoost 的 "Up"。
它提供“零停机时间重新加载”并另外创建多个工作人员(默认情况下 CPU 的数量,但它是可配置的)以提供所有世界中最好的。
它是新的,但似乎相当稳定,我在我当前的一个项目中愉快地使用它。
💢 重要区别 - 滚动重启
我必须添加在集群模式下使用节点构建与使用 PM2 集群模式等进程管理器之间的重要区别。
PM2 允许在您跑步时零停机时间重新加载。
pm2 start app.js -i 2 --wait-ready
在您的代码中添加以下内容
process.send('ready');
当您在代码更新后调用 pm2 reload app 时,PM2 将重新加载应用程序的第一个实例,等待“就绪”调用,然后继续重新加载下一个实例,确保您始终有一个激活的应用程序来响应请求。
而如果您使用 nodejs 的集群,当您重新启动并等待服务器准备好时将会有停机时间,因为只有一个应用程序实例并且您正在一起重新启动所有核心。
我为所有可用的 CPU 内核搜索了 Clusterize an app,并在这里找到了我自己。我在哪里找到这个关键字是 Pm2 命令
pm2 示例
这是我发现的
将应用程序集群到所有可用的 CPU 内核:$ pm2 start -i max
如果你需要安装 pm2 使用这些命令
npm install -g pm2
yan add -g pm2
或者
使用此链接 Here
也可以将 Web 服务设计为几个独立的服务器,监听 unix 套接字,这样您就可以将数据处理等功能推送到单独的进程中。
这类似于大多数脚本/数据库 Web 服务器架构,其中 cgi 进程处理业务逻辑,然后通过 unix 套接字将数据推送和拉取到数据库。
不同之处在于数据处理被编写为侦听端口的节点网络服务器。
它更复杂,但最终它必须去多核开发。为每个 Web 请求使用多个组件的多进程架构。
可以使用纯 TCP 负载均衡器 (HAProxy) 将 NodeJS 扩展到多个盒子,这些盒子在每个运行一个 NodeJS 进程的多个盒子前面。
如果您在所有实例之间共享一些常识,则可以使用中央 Redis 存储或类似存储,然后可以从所有流程实例(例如,从所有盒子)访问它

{kind=link}